
相信很多人都听过“雷神 3”关于性能优化的故事。在一个 3D 游戏引擎的源码里,John Carmack 将 1/sqrt(x) 这个函数的执行效率优化到了极致。
因为它是最底层的函数,而游戏里涉及到大量的这种运算,使得在运算资源极其紧张的 DOS 时代,游戏也可以流畅地运行。这就是性能优化的魅力!
工作中,当业务量比较小的时候,用的机器也少,体会不到性能优化带来的收益。而当一个业务使用了几千台机器的时候,性能优化 20%,那就能省下几百台机器,一年能省几百万。省下来的这些钱,给员工发年终奖,那得多 Happy!
一般而言,性能分析可以从三个层次来考虑:应用层、系统层、代码层。
应用层主要是梳理业务方的使用方式,让他们更合理地使用,在满足使用方需求的前提下,减少无意义的调用;系统层关注服务的架构,例如增加一层缓存;代码层则关心函数的执行效率,例如使用效率更高的开方算法等。
做任何事,都要讲究方法。在很多情况下,迅速把事情最关键的部分完成,就能拿到绝大部分的收益了。其他的一些边边角角,可以慢慢地缝合。一上来就想完成 100%,往往会陷入付出了巨大的努力,却收获寥寥的境地。
性能优化这件事也一样,识别出性能瓶颈,会让我们付出最小的努力,而得到最大的回报。
Go 语言里,pprof 就是这样一个工具,帮助我们快速找到性能瓶颈,进而进行有针对性地优化。
什么是pprof
代码上线前,我们通过压测可以获知系统的性能,例如每秒能处理的请求数,平均响应时间,错误率等指标。这样,我们对自己服务的性能算是有个底。
但是压测是线下的模拟流量,如果到了线上呢?会遇到高并发、大流量,不靠谱的上下游,突发的尖峰流量等等场景,这些都是不可预知的。
线上突然大量报警,接口超时,错误数增加,除了看日志、监控,就是用性能分析工具分析程序的性能,找到瓶颈。当然,一般这种情形不会让你有机会去分析,降级、限流、回滚才是首先要做的,要先止损嘛。回归正常之后,通过线上流量回放,或者压测等手段,制造性能问题,再通过工具来分析系统的瓶颈。
一般而言,性能分析主要关注 CPU、内存、磁盘 IO、网络这些指标。
Profiling 是指在程序执行过程中,收集能够反映程序执行状态的数据。在软件工程中,性能分析(performance analysis,也称为 profiling),是以收集程序运行时信息为手段研究程序行为的分析方法,是一种动态程序分析的方法。
Go 语言自带的 pprof 库就可以分析程序的运行情况,并且提供可视化的功能。它包含两个相关的库:
- runtime/pprof 对于只跑一次的程序,例如每天只跑一次的离线预处理程序,调用 pprof 包提供的函数,手动开启性能数据采集。
- net/http/pprof 对于在线服务,对于一个 HTTP Server,访问 pprof 提供的 HTTP 接口,获得性能数据。当然,实际上这里底层也是调用的 runtime/pprof 提供的函数,封装成接口对外提供网络访问。
作用
pprof 是 Go 语言中分析程序运行性能的工具,它能提供各种性能数据:

allocs 和 heap 采样的信息一致,不过前者是所有对象的内存分配,而 heap 则是活跃对象的内存分配。
- 当 CPU 性能分析启用后,Go runtime 会每 10ms 就暂停一下,记录当前运行的 goroutine 的调用堆栈及相关数据。当性能分析数据保存到硬盘后,我们就可以分析代码中的热点了。
- 内存性能分析则是在堆(Heap)分配的时候,记录一下调用堆栈。默认情况下,是每 1000 次分配,取样一次,这个数值可以改变。栈(Stack)分配 由于会随时释放,因此不会被内存分析所记录。由于内存分析是取样方式,并且也因为其记录的是分配内存,而不是使用内存。因此使用内存性能分析工具来准确判断程序具体的内存使用是比较困难的。
- 阻塞分析是一个很独特的分析,它有点儿类似于 CPU 性能分析,但是它所记录的是 goroutine 等待资源所花的时间。阻塞分析对分析程序并发瓶颈非常有帮助,阻塞性能分析可以显示出什么时候出现了大批的 goroutine 被阻塞了。阻塞性能分析是特殊的分析工具,在排除 CPU 和内存瓶颈前,不应该用它来分析。
使用方法
我们可以通过 报告生成、Web 可视化界面、交互式终端 三种方式来使用 pprof。
runtime/pprof
拿 CPU profiling 举例,增加两行代码,调用 pprof.StartCPUProfile 启动 cpu profiling,调用 pprof.StopCPUProfile() 将数据刷到文件里:
import "runtime/pprof"
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file")
func main() {
// …………
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
// …………
}
net/http/pprof
启动一个端口(和正常提供业务服务的端口不同)监听 pprof 请求:
import _ "net/http/pprof"
func initPprofMonitor() error {
pPort := global.Conf.MustInt("http_server", "pprofport", 8080)
var err error
addr := ":" + strconv.Itoa(pPort)
go func() {
err = http.ListenAndServe(addr, nil)
if err != nil {
logger.Error("funcRetErr=http.ListenAndServe||err=%s", err.Error())
}
}()
return err
}
pprof 包会自动注册 handler, 处理相关的请求:
// src/net/http/pprof/pprof.go:71
func init() {
http.Handle("/debug/pprof/", http.HandlerFunc(Index))
http.Handle("/debug/pprof/cmdline", http.HandlerFunc(Cmdline))
http.Handle("/debug/pprof/profile", http.HandlerFunc(Profile))
http.Handle("/debug/pprof/symbol", http.HandlerFunc(Symbol))
http.Handle("/debug/pprof/trace", http.HandlerFunc(Trace))
}
启动服务后,在与生产环境建立隧道后,直接在浏览器访问:
http://127.0.0.1:31108/debug/pprof/
就可以得到一个汇总页面:
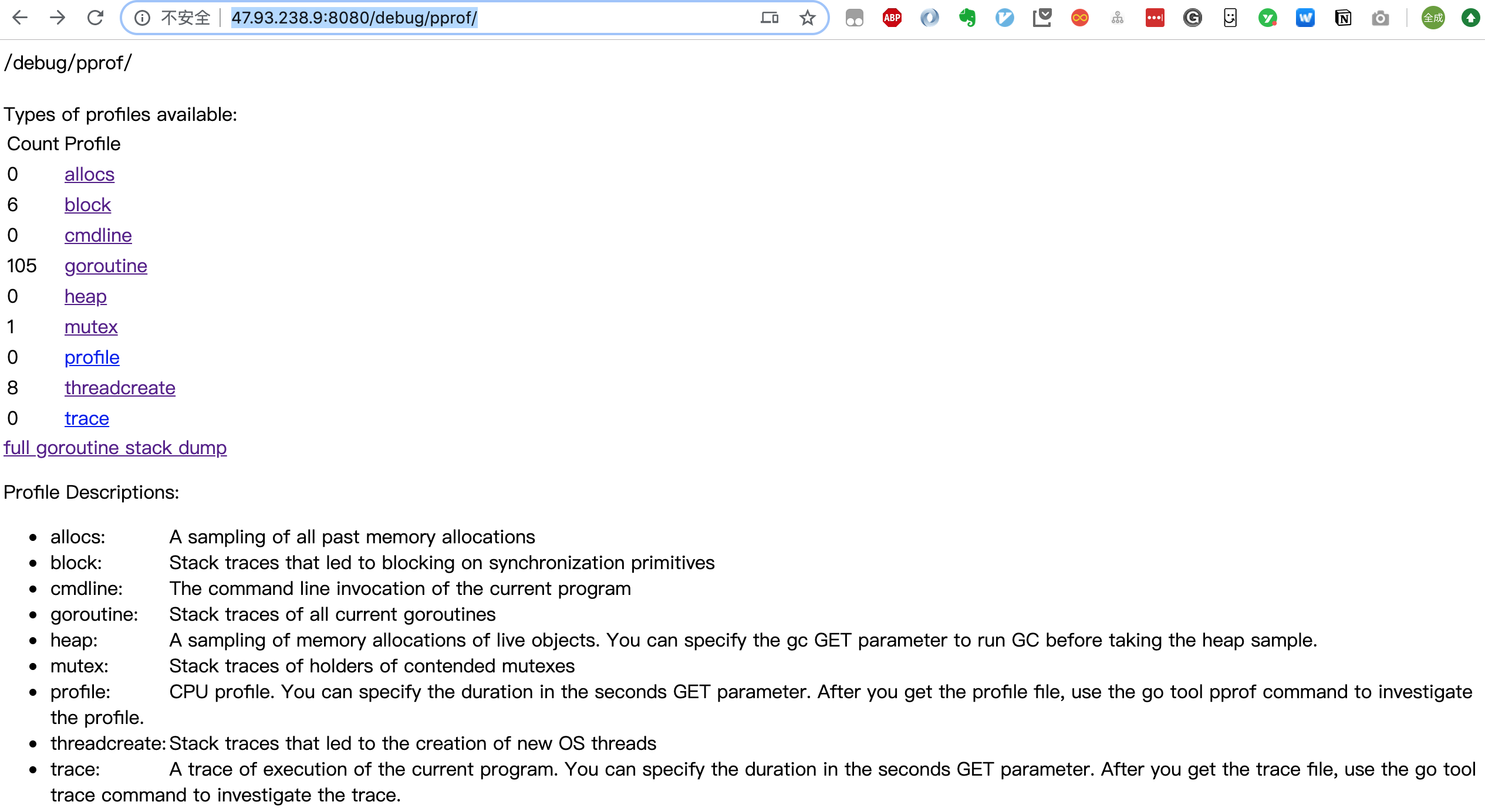
可以直接点击上面的链接,进入子页面,查看相关的汇总信息。
关于 goroutine 的信息有两个链接,goroutine 和 full goroutine stack dump,前者是一个汇总的消息,可以查看 goroutines 的总体情况,后者则可以看到每一个 goroutine 的状态。
点击 profile 和 trace 则会在后台进行一段时间的数据采样,采样完成后,返回给浏览器一个 profile 文件,之后在本地通过 go tool pprof 工具进行分析。
当我们下载得到了 profile 文件后,执行命令:
go tool pprof ~/Downloads/profile
就可以进入命令行交互式使用模式。执行 go tool pprof -help 可以查看帮助信息。
直接使用如下命令,则不需要通过点击浏览器上的链接就能进入命令行交互模式:
go tool pprof http://47.93.238.9:8080/debug/pprof/profile
当然也是需要先后台采集一段时间的数据,再将数据文件下载到本地,最后进行分析。上述的 Url 后面还可以带上时间参数:?seconds=60,自定义 CPU Profiling 的时长。
类似的命令还有:
# 下载 cpu profile,默认从当前开始收集 30s 的 cpu 使用情况,需要等待 30s
go tool pprof http://47.93.238.9:8080/debug/pprof/profile
# wait 120s
go tool pprof http://47.93.238.9:8080/debug/pprof/profile?seconds=120
# 下载 heap profile
go tool pprof http://47.93.238.9:8080/debug/pprof/heap
# 下载 goroutine profile
go tool pprof http://47.93.238.9:8080/debug/pprof/goroutine
# 下载 block profile
go tool pprof http://47.93.238.9:8080/debug/pprof/block
# 下载 mutex profile
go tool pprof http://47.93.238.9:8080/debug/pprof/mutex
进入交互式模式之后,比较常用的有 top、list、web 等命令。
执行 top
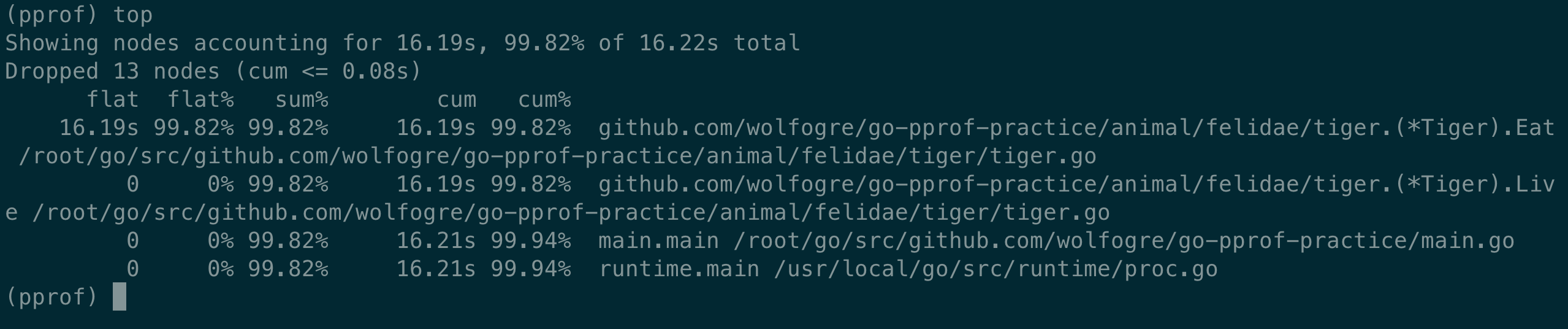

其他类型,如 heap 的 flat, sum, cum 的意义和上面的类似,只不过计算的东西不同,一个是 CPU 耗时,一个是内存大小。
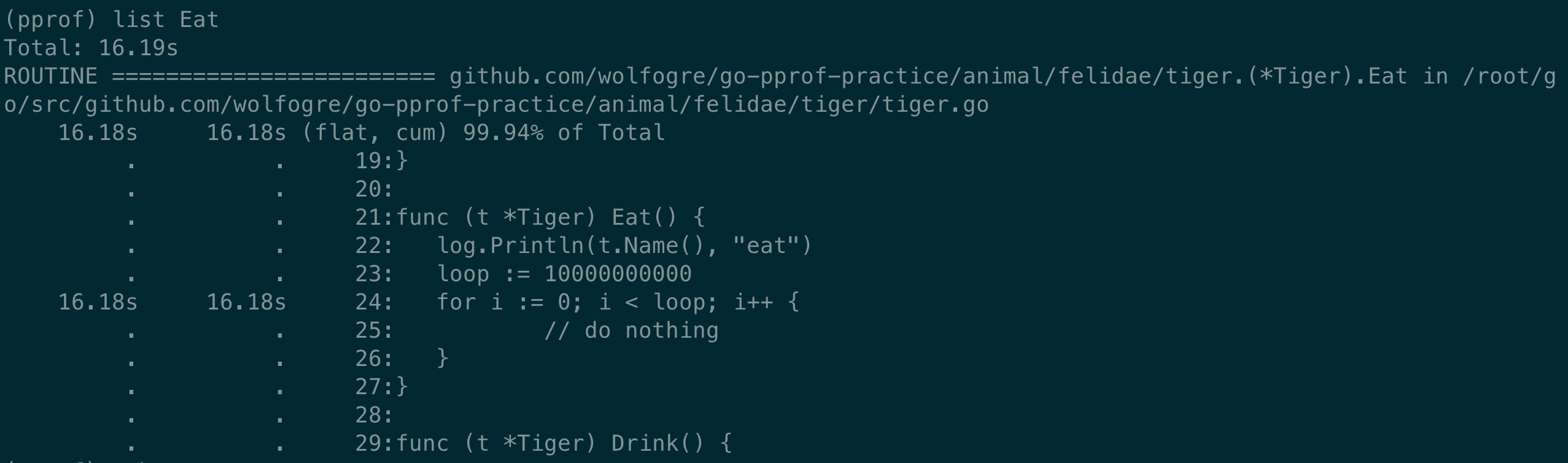
执行 list
使用正则匹配,找到相关的代码
list Eat
直接定位到了相关长耗时的代码处:
执行 web
(需要安装 graphviz,pprof 能够借助 grapgviz 生成程序的调用图),会生成一个 svg 格式的文件,直接在浏览器里打开(可能需要设置一下 .svg 文件格式的默认打开方式)
go tool pprof http:// localhost:31108/debug/pprof/profile
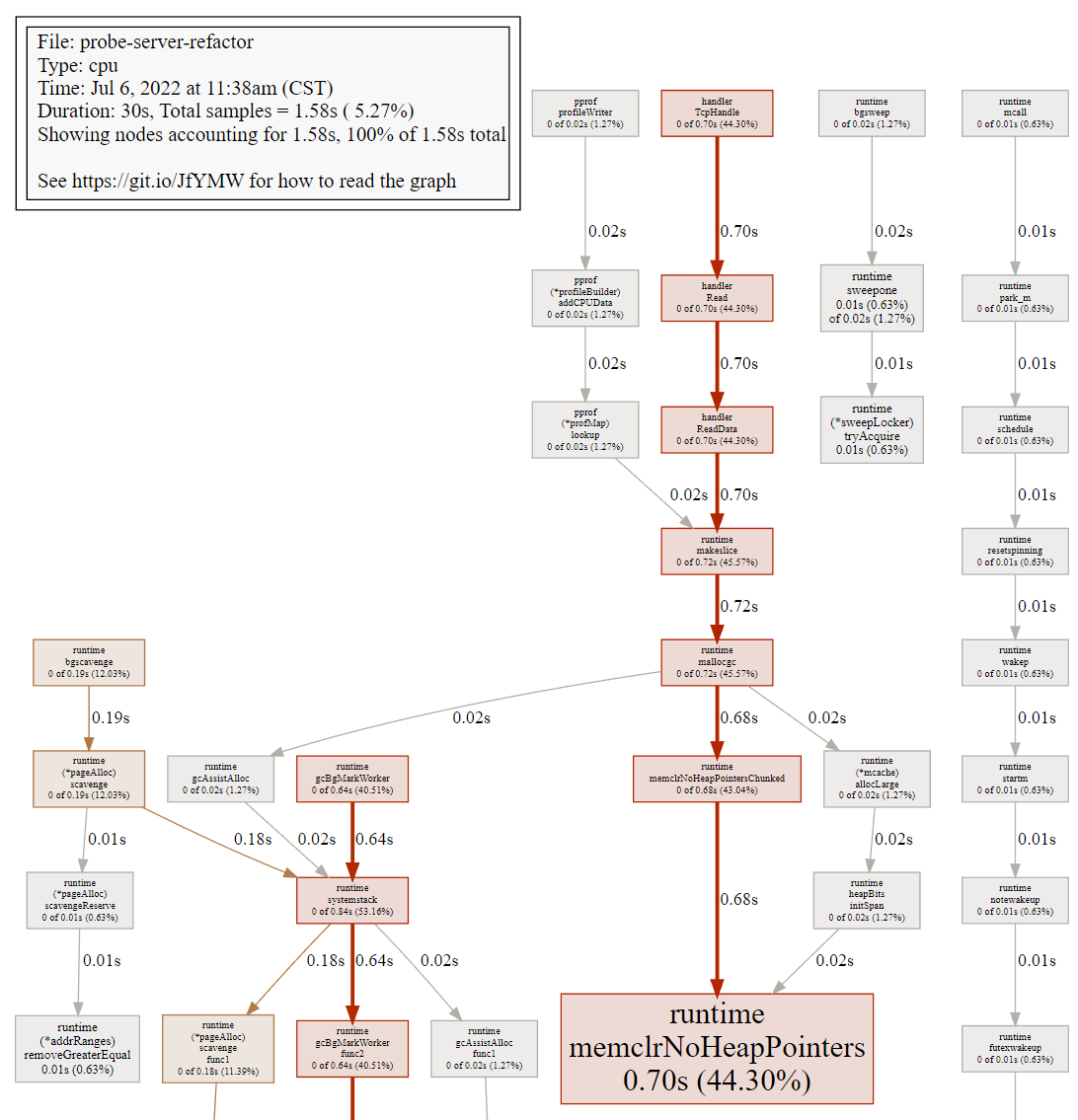
图中的连线代表对方法的调用,连线上的标签代表指定的方法调用的采样值(例如时间、内存分配大小等),方框的大小与方法运行的采样值的大小有关。
每个方框由两个标签组成:在 cpu profile 中,一个是方法运行的时间占比,一个是它在采样的堆栈中出现的时间占比(前者是 flat 时间,后者则是 cumulate 时间占比);框越大,代表耗时越多或是内存分配越多。
另外,traces 命令还可以列出函数的调用栈
除了上面讲到的两种方式(报告生成、命令行交互),还可以在浏览器里进行交互。先生成 profile 文件,再执行命令:
YEH!@LAPTOP-794D6PB5 MINGW64 /d/shixi/Documents/probe-server-profile
$ go tool pprof -http=:8080 ./profile
进入一个可视化操作界面:
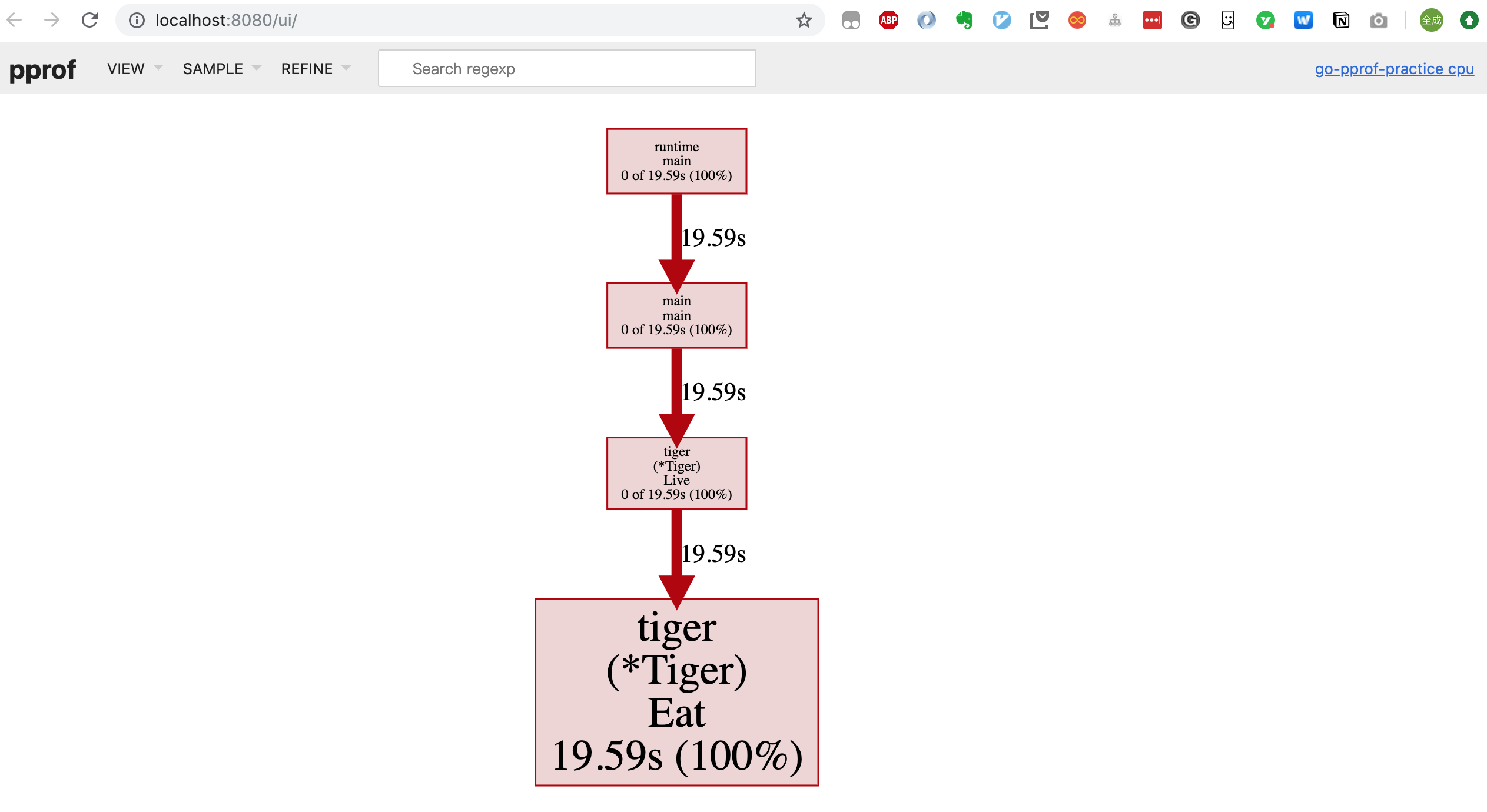
点击菜单栏可以在:Top/Graph/Peek/Source 之间进行切换,甚至可以看到火焰图(Flame Graph):
它和一般的火焰图相比刚好倒过来了,调用关系的展现是从上到下。形状越长,表示执行时间越长。