
更新记录一下实习产出~
一、优化流量平台服务
优化主流程中本地名单验证时,需要读取数据库的问题
取消本地验证名单时读mysql的操作,仅保留读redis的操作
更改redis上名单相关的ttl为永久,保证主流程的命中情况
缓存服务本地库更新问题
对定时更新本地失陷名单的方法进行补充,增添了对各名单中条目来源的判断(腾讯/安恒),并定时调用各自的API进行更新
二、 优化插件平台服务
网关扫描次数统计问题
对cacheHeartbeat新增ScanTimes,在扫描结束时增加对设备缓存的判断,在成功结束后,对扫描次数进行统计,并写入对应的gateway表中
新增查找出现故障插件功能
- 在每次心跳开始时对Plugin重启时间进行判定,从而找出出现故障(即重启过)的插件,及其对应的产品型号,写入缓存
- 新增对数据库gateway表中对heartbeat_time字段的增删查改
新增在线网关统计功能
- 在心跳时将该网关加入缓存的在线网关有序集合,以时间戳为score进行记录;
- 定时5s获取在线网关数,并将其纳入监控项送入Prometheus展示;
修改插件版本更新数量限制实现方式
- 使用ZSet对版本更新的数量变化进行记录,score初始设置为定值,随着版本更新修改对应插件已更新数量,从而可以在Redis中动态地进行观测;
新增扫描结果记录功能
添加scan_gateway, scan_device, scan_cpe 三张表,用于存储扫描结果;
在finish_ gateway _scan 方法中,通过request数据中的网关mac与pppoe在gateway表中查询对应的id,将其与此时记录的时间存入scan_gateway表中;
再通过gatewayMac和pppoe查询在扫描设备列表时记录的缓存数据,根据查到的deivceMac在device表中查询对应的id与type,将其存入scan_device表中;
在存cpe信息时,发现由于此前在match_probe方法中,未对cpe信息进行保存,缓存中只有leak相关信息,因此在match_probe中添加一个Redis哈希表来记录每台设备的各个端口对应的cpe相关信息;
进而回到finish_ gateway _scan 方法中,对设备的每一个端口,通过在缓存中查询得到的对应的cpe相关信息,在cpe表中查询对应的cpeId,将其和端口、服务等信息存入scan_cpe表中;
上述三个表通过scan_id、scan_device_id进行关联,需要保证参照完整性;
优化Ping_failed请求处理方式
现有处理方式: 在每次接收到ping_failed请求后,在Redis对对应设备的string key, value +1,当大于等于10次后,返回“不要再扫描”的回复,并异步执行updatePingFailedDeviceStatus,删除Redis中对应key, 并将数据库中设备IsDisablePing字段设置为1;
现有问题:由于updatePingFailedDeviceStatus方法中直接将缓存清空,所以对于某些一直无法ping通的设备,每一轮扫描时,都需要对该设备ping10次才能停止扫描,浪费了大量时间;
解决方法:在updatePingFailedDeviceStatus中,不再直接删除该key,而是通过在外部设置TTL,使得一段时间内收到该设备的ping_failed后,都直接返回停止扫描,提高qps;
三、问题研究与报告撰写
流量平台服务中gRPC负载均衡失效问题研究
k8s中,由于gRPC框架基于HTTP2.0,会出现负载均衡失效的问题,对该问题进行了研究,找到对应的解决方案并撰写了相关报告
高危端口及解决方案研究
对135、139、445三个高危端口的概念、漏洞风险以及关闭和开启方法进行学习研究,并撰写报告提交
Redis与Mysql一致性问题研究
流量平台中各类名单同时存储在Redis及Mysql数据库中,因此需要保证二者的一致性,对其一致性实现方式进行了学习并撰写了相关报告
撰写流量平台业务流程说明文档
将流量平台的业务通过流程图可视化,并撰写文档解释说明
撰写云宽带-安全方案文档
介绍我们的业务能力,以及简要的流程
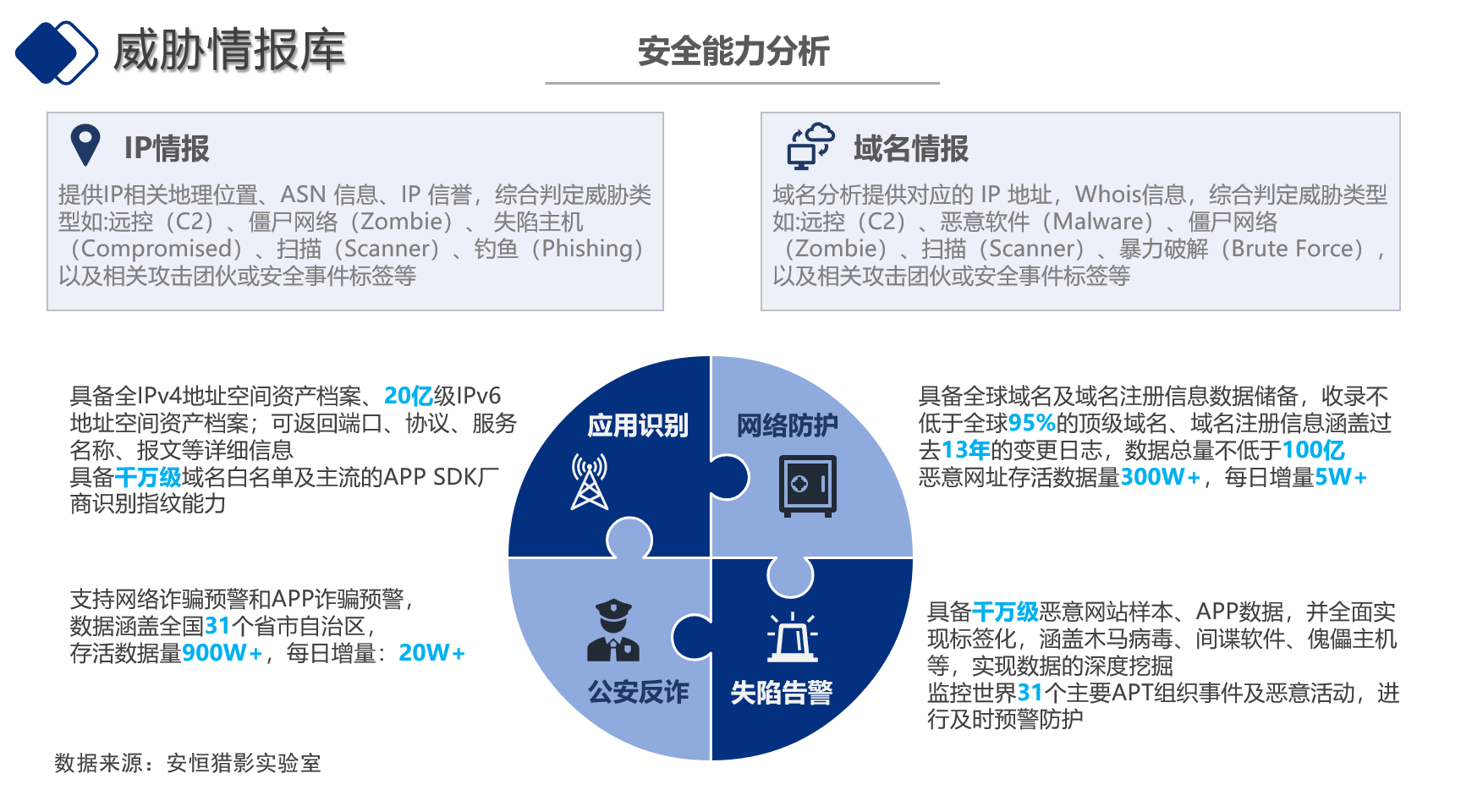
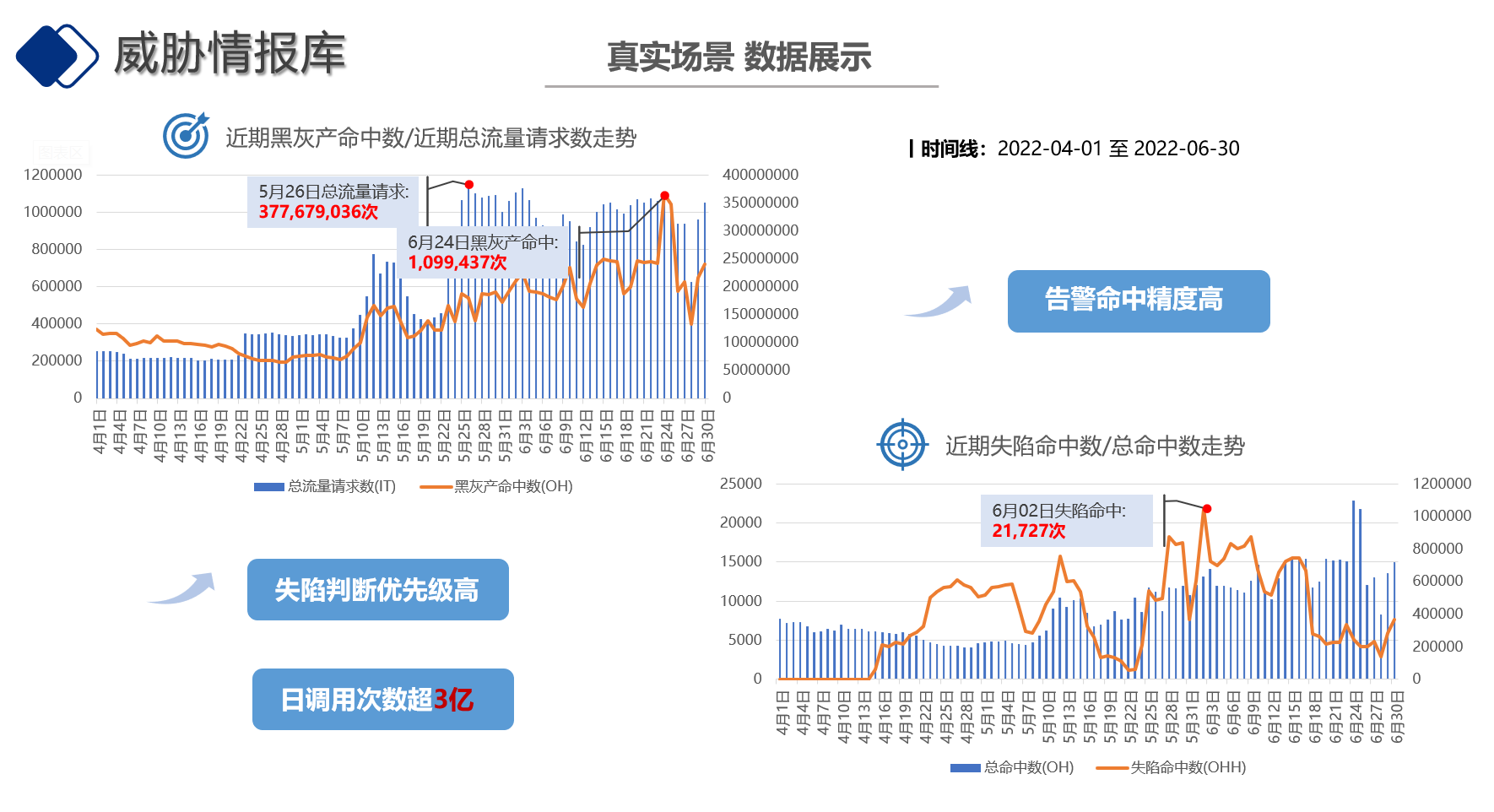
制作威胁情报库slide
分析展示威胁情报库能力

四、为所有服务端增添Prometheus监控
对现有的四个服务:traffic-report-server、traffic-cache-server、traffic-context-consumer、probe-server-refactor添加Prometheus监控,连接grafana对统计信息进行图形化动态输出
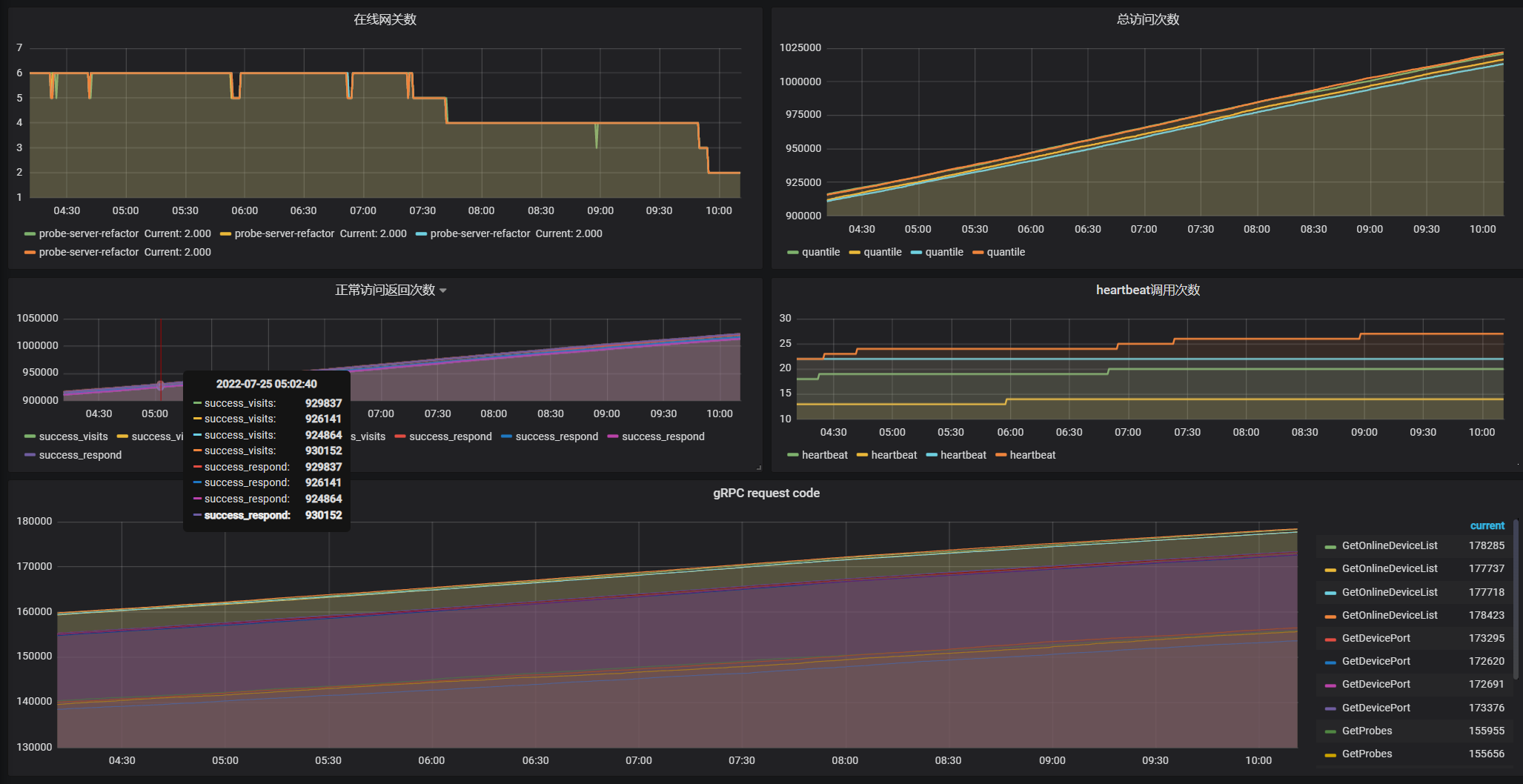
Probe-server添加监控
分别使用gauge和counter数据类型对总访问次数、正常访问次数、正常返回次数、TCP各个方法调用次数、在线网关数添加Prometheus监控

五、对服务监控定位
通过kubectl对probe-server的pods进行监控
监控K8s下的probe-server的Pods, 出现问题时及时反馈,并通过日志定位
通过pprof对出错位置定位
学习pprof的使用方式,通过它来对生产环境中出现的问题进行定位
六、其他
解析生成旧版plugin_name对照表
通过向probe-server原始版本的服务发送请求,分析返回的内容,得到product_class,probe_version与plugin_name的对照表